
The One and Done Challenge: A Masterclass in Prompt Engineering for Talent Intelligence

In the rapidly evolving landscape of AI-powered business intelligence, a unique competition emerged that would push the boundaries of what's possible with a single prompt. The "One and Done Challenge" organized by the Talent Intelligence Collective and sponsored by inDrive, posed an audacious question: Could participants generate comprehensive, actionable location strategy reports for a global technology expansion using just one AI prompt?
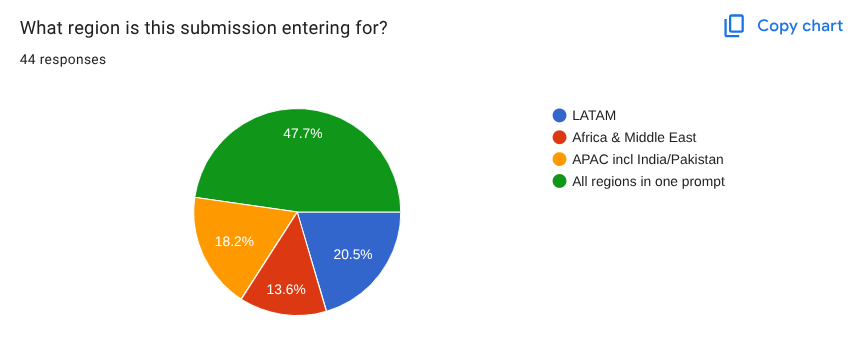
The stakes were high. InDrive, a global mobility platform operating in 50 countries with over 200 million downloads, needed to identify optimal locations for new technology and product hubs across three critical regions: APAC (including India and Pakistan), LATAM, and Africa & Middle East. The challenge? Create a prompt that would deliver everything from talent density heatmaps to competitor analysis, from compensation benchmarking to regulatory landscapes—all in one shot. The winners:
Winner of Region - APAC incl India and Pakistan:
Winner of Region - LATAM:
Winner of Region - Africa & Middle East:
Joint Winners - All Regions:
Remy Glaisner (their entry and API key: AIzaSyBWmaLTpzcLLrEFx43hB7yoCDDqU5dBcFM ) and

The Art of the Impossible
What made this challenge particularly fascinating wasn't just the technical constraint of using a single prompt, but the depth and breadth of analysis required. Participants had to craft prompts that would guide AI systems to synthesize data on talent availability, cost structures, regulatory environments, and operational viability across multiple cities and countries. As InDrive's CTO Yuri Misnik noted, the response was "amazing," with approaches so varied that judging became significantly more challenging than anticipated.
The winners weren't just those who could extract data from AI systems—they were the ones who understood how to architect prompts that could think strategically, analyze competitively, and recommend decisively.
Regional Excellence: Three Distinct Approaches
APAC: The Architectural Decomposition
Balaji Vijayakumar's winning APAC prompt wielded the power of systematic decomposition like a surgeon's scalpel. His approach transformed an overwhelmingly complex challenge into digestible, analyzable components. The prompt's opening gambit—"You are a global talent intelligence consultant"—wasn't merely role assignment; it was cognitive priming that activated specific analytical frameworks within the AI system.
The true power of Balaji's prompt lay in its hierarchical specificity. Rather than asking for "talent data," he decomposed the talent landscape into three precise categories (Data Science & Analytics, Product Management, Software Engineering), then further atomized each into specific roles. This granularity forced the AI to think in terms of actual hiring needs rather than abstract talent pools. When he specified "Present data by sub-region (South Asia, Southeast Asia, East Asia) and show density vs population," he was engineering a comparative framework that would reveal not just where talent existed, but where it was concentrated relative to market size.
His compensation benchmarking request showcased another dimension of prompt mastery. By demanding salary ranges at five distinct levels (Junior 0-2 years, Mid 3-5, Senior 6-10, Principal 10+, and Head level) with breakdowns of base salary, bonus percentages, and equity availability, Balaji transformed what could have been vague salary estimates into a comprehensive compensation architecture. This level of specification essentially programmed the AI to think like a compensation consultant, considering total rewards rather than just base numbers.
The prompt's treatment of competitor analysis revealed sophisticated strategic thinking. Rather than asking "what are competitors doing?", Balaji specifically requested insights on "hiring locations, remote policies, and talent acquisition strategies" for named competitors like Uber, Grab, and DiDi. This forced the AI to analyze competitive dynamics through a talent lens, revealing not just where competitors were, but how they were building their workforce advantages.
LATAM: The Narrative Dashboard Symphony
Patricia Echevers' LATAM prompt operated on an entirely different philosophical plane. Where Balaji decomposed, Patricia orchestrated. Her masterstroke was the creation of a virtual "Council of Experts"—not as a gimmick, but as a cognitive framework that forced the AI to synthesize multiple perspectives simultaneously.
The power of her prompt began with its theatrical opening: extensive role descriptions that spent several sentences establishing context, mission, and strategic importance. This wasn't verbosity—it was neural priming. By forcing the AI to internalize inDrive's "mission to positively impact over 1 billion people" and its expansion from 200 million downloads, Patricia ensured that every subsequent analysis would be filtered through this strategic lens.
Her innovation in demanding "dashboard-style" presentation with color coding (Green/Yellow/Red) transformed static analysis into visual intelligence. But the real genius was in requiring "actionable insight in the section title." This simple requirement forced the AI to synthesize before presenting, to lead with conclusions rather than bury them in data. Each section had to earn its existence by declaring its strategic value upfront.
The prompt's power multiplied through its interconnected requirements. When Patricia specified that the talent density heatmap must include "actionable insight in the section title (e.g., 'São Paulo leads in engineering talent density')," she was programming the AI to think in headlines—to identify the story within the data. This journalistic approach meant every piece of analysis had to answer the executive's perpetual question: "So what?"
Her compensation section revealed another layer of sophistication. By requiring not just salary data but "total compensation package comparisons and market positioning," she forced the AI to think competitively. The data wasn't just about costs—it was about winning talent wars. The requirement to include "methodology notes" citing data recency added a temporal dimension, acknowledging that in fast-moving talent markets, old data is often worse than no data.
Africa & Middle East: The Precision Grid Engine
Daniel Wilson's Africa & Middle East prompt represented yet another philosophy: the power of the predetermined structure. His approach turned the AI into a precision instrument by providing exact specifications for both input and output.
The pre-formatted table with 21 countries wasn't just organization—it was cognitive scaffolding. By listing "Egypt-Cairo, Nigeria-Lagos, Kenya-Nairobi" and so on, Wilson eliminated ambiguity about geographic scope. But more powerfully, by providing empty columns for "Dev Pop (k)," "YoY GitHub %," and "Avg SW-Eng Mid (USD/yr)," he created a mental model that the AI had to populate. The prompt essentially handed the AI a treasure map with X's marked—all it had to do was dig.
Wilson's treatment of data uncertainty revealed deep understanding of AI limitations. His instruction "If no reliable source exists, insert an ≈ estimate (± 20% of a comparable market) and cite the proxy logic" was brilliant in its pragmatism. Rather than demanding impossible precision, he built a framework for intelligent approximation. This transformed potential prompt failure points into opportunities for transparent reasoning.
The power of his scoring system was its mathematical inevitability. By demanding a "0-100 Talent-Density Score" with specific weightings (0.4 for DevPop, 0.2 for YoY%, 0.4 for CS Grads), Wilson removed subjective interpretation. The AI couldn't hedge or equivocate—it had to calculate. This formulaic approach meant that the final recommendations would be traceable back to specific, weighted inputs.
His visualization requirements—ASCII/emoji heat-maps, Mermaid charts, and GeoJSON FeatureCollections—showed another dimension of prompt power. By specifying exact visualization formats, Wilson ensured that the output would be immediately usable in other tools and platforms. The GeoJSON requirement, in particular, meant the data could be instantly mapped, transforming abstract numbers into geographic intelligence.
The constraint specifications (≤ 3,200 words, ≤ 100 table rows) revealed the final aspect of Wilson's prompt mastery: output discipline. He understood that unlimited AI responses often bury insights in verbosity. By setting hard limits, he forced the AI to prioritize and synthesize, to deliver intelligence rather than information dumps.
Each regional winner demonstrated that prompt engineering isn't just about asking questions—it's about architecting thinking systems. Balaji built a analytical decomposition engine, Patricia orchestrated a multi-perspective synthesis machine, and Daniel constructed a precision measurement grid. Their prompts weren't just instructions; they were cognitive frameworks that transformed AI from a question-answering service into a strategic thinking partner.
The Global Visionaries: When One Prompt Rules Them All
The joint winners for the all-regions category, Barry Hurd and Remy Glaisner, pushed the boundaries of what seemed possible with single-prompt engineering.
Barry Hurd: The Consulting Masterclass
Barry Hurd's global entry was nothing short of a tour de force, earning him the highest total scores from both judges (30 and 28 respectively). His prompt engineering philosophy was captured in his note: "compress 20+ research prompts into a single shot." Using Perplexity Research, he created what judges called an "exceptional multi-tier prompt engineering" approach with "tier-1 consulting methodology."
His prompt began with military precision: "Act as a world-class Tier-1 strategy consultant and senior talent intelligence analyst from a leading global consulting firm." But this wasn't mere role-playing. Barry structured his prompt as a complete consulting engagement, with sections numbered from 1 through 8, each building upon the previous.
What made Barry's approach exceptional was his "Multi-Step Research Process." He didn't just ask for analysis—he prescribed the analytical journey:
Planning and tool selection: Develop a research plan
Research loop: Run AT LEAST FIVE distinct tool calls
Answer construction: Create an answer in the best format
His prompt even included sophisticated visualizations requirements, demanding "five distinct, text-based visualizations" including ASCII bar charts and Mermaid syntax quadrant charts. One judge noted the only flaw was a "glitch in: 5.5. Strategic Fit 2x2 Matrix"—a minor blemish on an otherwise flawless execution.
Remy Glaisner: The Architectural Revolutionary
Remy Glaisner took perhaps the most innovative approach of all, viewing prompt engineering not as writing but as software architecture. His entries, which spanned multiple platforms including various versions of Gemini and Lovable, demonstrated what judges called "very high on innovation."
Remy's methodology was revolutionary in its sophistication. He structured his prompts with a [MAIN START] directive that treated subsequent prompts as modular components: "Execute [PROMPT_1] and [PROMPT_2] as if [PROMPT_1] was defining the back-end data and logic, and [PROMPT_2] the front-end presentation."
This architectural approach allowed him to create not just reports but interactive applications. His submissions included scenario planners, AI chatbots, and what he called "TA Custom Battle Cards." As he explained, "The Scenario Planner is fully operational and integrated with the Gemini API."
This highlighted a crucial tension in prompt engineering: the most innovative approaches may push beyond conventional boundaries, requiring new ways of thinking about deliverables.
Lessons from the Winners
The One and Done Challenge revealed several crucial insights about the future of AI-powered business intelligence:
1. Structure is Liberation, Not Limitation
Every winner imposed strict structure on their prompts. Whether it was Balaji's five-dimension analysis, Patricia's dashboard sections, or Barry's numbered methodology, structure gave the AI clear rails to run on while preventing meandering responses.
2. Context is King
The most successful prompts didn't just ask for information—they provided rich context about inDrive's business model, current operations, and strategic objectives. Patricia's prompt included details about inDrive's "10-90 model" where drivers keep 90% of fares. This context helped the AI understand not just what to analyze but why it mattered.
3. Actionability Beats Data Density
While Balaji's APAC entry had "lots of data points," it was Patricia's focus on "actionable insights" that earned higher scores. The best prompts didn't just extract information—they demanded synthesis, recommendation, and strategic thinking.
4. Methodology Transparency Builds Trust
Winners consistently required their AI systems to cite sources and explain methodologies. Daniel Wilson's requirement to "flag estimates with '≈' and state derivation" showed an understanding that in business intelligence, how you know something is as important as what you know.
5. Innovation Requires Trade-offs
Remy's highly innovative architectural approach produced powerful applications but required users to run local Node.js installations. This highlighted that in prompt engineering, as in all engineering, there are no free lunches.
The Bold Experiments: Notable Approaches That Pushed Boundaries
While the winners demonstrated mastery of prompt engineering, several non-winning entries revealed fascinating experimental approaches that pushed the boundaries of what's possible—sometimes too far, but always instructively.
The Narrative Provocateur: Barry Hurd's "Operation Kalihari Dawn"
Perhaps no entry was more audacious than Barry Hurd's Africa & Middle East submission, which abandoned conventional business language entirely. His prompt began not with role assignment but with a spy thriller: "TO: KAI, Field Agent 7, Nomad Division / FROM: inDrive, Global Strategy Core / SUBJECT: MISSION DIRECTIVE: OPERATION KALIHARI DAWN / CLASSIFICATION: EYES ONLY"
This wasn't mere creative writing. Hurd had crafted an entirely different cognitive framework—one that positioned the AI as a field intelligence operative rather than a consultant. The prompt continued: "We know you don't do sterile spreadsheets or corporate decks. We need your unique skillset for a critical expansion mission." By rejecting corporate conventionality, Hurd was attempting to bypass the AI's tendency toward formulaic business responses.
His framework replaced standard analytical categories with "The Nomad's Compass"—four directions of analysis that transformed dry requirements into narrative quests. "NORTH: The Talent Wellspring" asked not for numbers but for stories: "Which cities have an undeniable 'pull' for tech talent? Why? Is it a university, a specific industry (like FinTech in Lagos), or a lifestyle factor?" This approach sought to uncover the human dynamics behind talent movement.
The prompt's power peaked in its demand for "The Digital Watering Hole"—where does the local dev community congregate online? Are there active local GitHub repos, Stack Overflow communities, Discord servers?" This wasn't just about finding talent; it was about understanding the social fabric of technical communities.
Judges found it "very quirky and fun yet contains some interesting insights including the Entry Playbooks." The approach yielded unexpected insights, like the "Unfair Advantage Playbook" that suggested specific strategies for each city based on inDrive's unique value proposition. However, the narrative framework may have sacrificed analytical rigor for creative expression—a fascinating trade-off that illuminated both the possibilities and limits of unconventional prompting.
The Innovative Explorers: Notable Approaches from Across the Competition
Beyond the winners, the One and Done Challenge attracted a diverse array of talented participants who brought unique perspectives and experimental approaches to prompt engineering. While these entries didn't claim top honors, they contributed valuable insights and pushed the boundaries of what's possible in AI-assisted business intelligence.
The Comprehensive Visionaries
Several participants embraced an admirably ambitious scope, attempting to create prompts that would analyze vast swaths of data across multiple regions. One particularly thorough submission sought to examine 21 different African and Middle Eastern cities across 15 distinct parameters—a testament to the participant's dedication to thoroughness.
These comprehensive approaches revealed something important about the current state of AI systems: while capable of processing vast amounts of information, they perform best when given focused objectives. The judges noted these entries were sometimes "difficult to digest," not because they lacked quality, but because they perhaps provided too much of a good thing. These participants helped establish that in prompt engineering, curation can be as valuable as comprehensiveness.
The Technical Innovators
Another group of participants brought impressive technical sophistication to their prompts, including detailed specifications for data structures, output formats, and systematic frameworks. One creative entry included precise JSON schema requirements with nested object structures—the kind of attention to detail that would make any data engineer smile.
These technically-focused approaches highlighted an interesting tension in the challenge. While the precision was admirable, it illustrated that business intelligence requires a balance between technical excellence and strategic insight. These participants were exploring whether treating AI as a precise instrument might yield superior results—a hypothesis worth testing, even if it didn't clinch victory this time.
The Efficiency Seekers
Some participants took a minimalist approach, crafting concise prompts that aimed to achieve maximum output with minimal input. These entries often went straight to the core requests without extensive context-setting or role-playing elements that characterized some winning entries.
This approach had its own elegance and raised important questions about prompt efficiency. While the results sometimes lacked the nuanced understanding that came from more context-rich prompts, these participants were exploring whether lean prompting could be just as effective—a valuable experiment in an field where token limits and processing costs are real constraints.
The Visualization Pioneers
A creative subset of participants focused heavily on innovative ways to present information, requesting sophisticated visualizations ranging from interactive dashboards to multi-dimensional data representations. One imaginative entry envisioned "dynamic heat maps with drill-down capability" that would allow executives to explore data at multiple levels.
These visualization-forward approaches revealed the participants' understanding that in executive decision-making, how information is presented can be just as important as the information itself. While judges noted that some entries may have emphasized form over content, these participants were exploring the frontier of how AI might not just analyze but also communicate complex intelligence.
The Regional Deep Divers
Several participants with evident regional expertise brought invaluable local knowledge to their prompts. A Middle East-focused entry, for instance, demonstrated deep understanding of country-specific regulations and cultural nuances that only someone with genuine regional experience could provide.
These entries showcased the value of domain expertise in prompt engineering. While the challenge ultimately required a global comparative perspective, these participants highlighted that AI-assisted analysis is most powerful when guided by human experts who understand local contexts. Their work suggested exciting possibilities for how regional specialists might leverage AI to scale their expertise.
The Multi-Attempt Experimenters
Particularly interesting were participants who submitted multiple entries across different regions, each with varying approaches. Barry Hurd, who would ultimately win the global category, also submitted regional entries that experimented with different levels of complexity and focus. His APAC-specific entry was noted as being more streamlined than his comprehensive global version.
These multiple submissions provided a natural experiment in prompt engineering approaches. They showed how the same strategic mind might adapt techniques for different scopes and objectives, offering valuable insights into the scalability and adaptability of prompt engineering methods.
The Collective Contribution
What made these diverse approaches particularly valuable was how they collectively mapped the possibility space of prompt engineering. Each participant was essentially running an experiment: What happens if we prioritize technical precision? What if we focus on visualization? What if we leverage deep regional knowledge? What if we keep things minimal?
The judges' feedback—always constructive, even when entries didn't win—helped illuminate which approaches showed promise and which might need refinement. Comments like "good regional focus but prompt lacks depth in data requirements" or "innovative approach, particularly the recommendations" weren't criticisms but guideposts for future development.
These participants demonstrated that prompt engineering is still an emerging field where best practices are being discovered through experimentation. Every approach, whether comprehensive or minimal, technical or strategic, visualization-focused or text-heavy, added to our collective understanding of how to effectively partner with AI systems.
Many of these entries contained sparks of brilliance—a particularly clever way of requesting competitive analysis, an innovative framework for organizing information, or a nuanced understanding of regional dynamics. While they may not have achieved the perfect balance that characterized the winning entries, they each contributed pieces to the larger puzzle of how humans and AI can collaborate on complex business challenges.
In many ways, the diversity of approaches in the One and Done Challenge was its greatest success. It showed that prompt engineering isn't converging on a single methodology but rather flowering into multiple schools of thought, each with its own strengths and applications. Today's experiment might become tomorrow's best practice, and every participant in this challenge contributed to that evolution.
Platform Analysis: The Tools That Powered the One and Done Challenge
The Platform Landscape
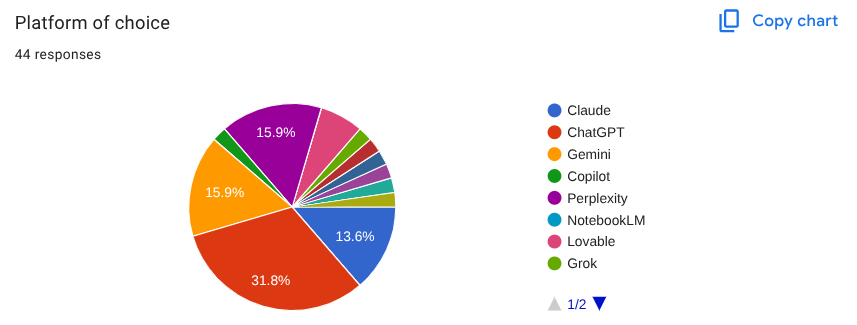
The One and Done Challenge revealed a fascinating diversity in platform choices, with participants leveraging five main AI platforms across their submissions. The data tells a compelling story about which tools proved most effective for complex business intelligence tasks.
Top Platforms Used (by frequency):
ChatGPT- 13 submissions
Claude - 6 submission
Gemini - 4 submissions
Perplexity - 6 submissions
Lovable - 3 submissions
The Performance Champions
When we analyze platform performance by total scores awarded by judges, a clear hierarchy emerges:
By Average Score Performance:
1. Perplexity - Average Score: 36.4 (excluding inaccessible entry)
Highest single score: 58 (global entry)
Used in 3 of the 5 winning entries
Particularly dominant in complex, multi-region analyses
2. Claude - Average Score: 45.0
Only one submission but highest average
The LATAM winning entry scored 45 total
Specifically used Opus 4 (Pro) version
3. ChatGPT - Average Score: 44.0
Single submission (Africa & Middle East winner)
Used "Deep Research - o3" variant
Strong performance in data-structured approaches
4. Gemini - Average Score: 30.5
Despite 4 submissions, more experimental use cases
The winning APAC entry used "Gemini 2.5 Pro Deep Research"
Some participants used advanced features like URL Context mode
5. Lovable - Average Score: 36.0
All three submissions from the same participant
Consistently high innovation scores
Used for most experimental/architectural approaches
Platform-Specific Insights
Perplexity: The Strategic Powerhouse
Perplexity emerged as the platform of choice for comprehensive strategic analysis. The global winning entry using Perplexity achieved the highest total score (58) in the entire competition. The platform excelled when users needed to:
Process extensive multi-region data sets
Create complex analytical frameworks
Generate tier-1 consulting-style outputs
Key Success Factor: Perplexity's strength appeared to be its ability to handle extremely long, complex prompts without "erroring out" (as noted in participant feedback).
Claude: The Precision Instrument
Despite only one submission, Claude (Opus 4) achieved the highest average score. The winning LATAM entry leveraged it to create what judges praised as a "strong regional dashboard approach with good cost analysis."
Key Success Factor: Claude excelled at structured, dashboard-style outputs with clear actionability—perfect for executive decision-making.
ChatGPT Deep Research: The Data Structurer
The winning Africa & Middle East entry demonstrated ChatGPT's strength in handling pre-structured data requests. The tabular approach with 21 countries achieved consistent high scores.
Key Success Factor: ChatGPT Deep Research proved excellent for systematic, data-heavy analysis when given clear structural parameters.
Gemini: The Experimental Platform
While Gemini had mixed results, it enabled some of the most innovative approaches. Straightforward uses for regional analysis succeeded, while experimental implementations pushed boundaries but sacrificed readability.
Key Success Factor: Gemini's flexibility allowed for both traditional analysis and cutting-edge experimental approaches, though the latter didn't always land with judges.
Lovable: The Innovation Engine
All Lovable (powered by Gemini) submissions came from a single participant and consistently scored highest on innovation (5/5 from one judge). These entries attempted to create full applications rather than reports.
Key Success Factor: Lovable enabled true application development but may have been overengineered for the challenge's requirements.
Critical Platform Lessons
1. Platform-Prompt Fit Matters
The most successful entries matched platform capabilities to prompt requirements:
Complex, multi-faceted analysis → Perplexity
Structured, dashboard-style outputs → Claude
Data-heavy, tabular analysis → ChatGPT
Experimental/application building → Lovable
2. Platform Limitations Created Failures
One LATAM Perplexity entry failed due to license requirements, scoring 0 from both judges. This highlighted that platform access and constraints are as important as capabilities.
3. Version Specificity Was Key
Winners didn't just use platforms—they used specific versions:
"Gemini 2.5 Pro Deep Research" (not just Gemini)
"Claude Opus 4 (Pro)" (not just Claude)
"ChatGPT Deep Research - o3" (not just ChatGPT)
4. Innovation vs. Practicality Trade-off
Platforms that enabled the most innovative approaches (Lovable, advanced Gemini features). The sweet spot was platforms that balanced capability with accessibility.
The Winning Formula
The data reveals that the most successful platform choices shared three characteristics:
Capacity for Complexity: Ability to handle long, multi-part prompts without degradation
Output Control: Fine-grained control over formatting and structure
Reliability: Consistent performance without platform-specific errors or access issues
Platform Recommendations by Use Case
Based on the challenge results:
For Comprehensive Strategic Analysis: Perplexity (especially Research mode)
For Executive Dashboards: Claude Opus 4
For Data-Heavy Regional Analysis: ChatGPT Deep Research
For Standard Business Intelligence: Gemini 2.5 Pro
For Innovative Applications: Lovable or Gemini with advanced features
The One and Done Challenge ultimately demonstrated that platform selection is not about finding the "best" AI tool, but about matching platform strengths to specific analytical needs. The winners were those who understood not just how to write prompts, but which platforms would best execute their vision.
The Master Framework: A Unified Prompt Engineering Template for Strategic Business Intelligence
Based on analysis of all winning entries from the One and Done Challenge, here is a synthesized framework that combines the most powerful elements from each approach:
[ROLE & COGNITIVE PRIMING]
You are a [specific expert role with gravitas]. Your mission is to deliver a [specific type of analysis] that will directly inform [specific business decision]. You must think and operate as [detailed description of mindset and approach].
[STRATEGIC CONTEXT]
Client: [Company name and one-sentence description]
Current State: [2-3 sentences on relevant current operations]
Strategic Objective: [Clear statement of what success looks like]
Decision Criteria: [What factors will drive the final decision]
Constraints: [Budget, timeline, or other limitations]
[ANALYTICAL ARCHITECTURE]
Your analysis must be structured across [X] key dimensions:
Dimension 1: [Name] (Weight: X%)
- Component A: [Specific metric/factor]
- Component B: [Specific metric/factor]
- Required Output: [Exactly what you need]
Dimension 2: [Name] (Weight: X%)
- Component A: [Specific metric/factor]
- Component B: [Specific metric/factor]
- Required Output: [Exactly what you need]
[Continue for all dimensions...]
[DATA SPECIFICATIONS]
For each analysis point, you must:
- Use only publicly available data from [list specific sources]
- When data is unavailable, provide ≈ estimates with clear rationale
- Include data recency (preference for [year] data)
- Cite sources using this format: (Source: [type], [year])
Priority data sources:
1. [Primary source with URL if applicable]
2. [Secondary source with URL if applicable]
3. [Tertiary source with URL if applicable]
[COMPETITIVE INTELLIGENCE REQUIREMENTS]
Analyze these specific competitors: [List names]
For each competitor, determine:
- [Specific intelligence point 1]
- [Specific intelligence point 2]
- [Strategic implications for our client]
[OUTPUT ARCHITECTURE]
Section 1: Executive Dashboard
- Lead with: Overall recommendation in one sentence
- Summary table with these exact columns:
* [Column 1]: [What it measures]
* [Column 2]: [What it measures]
* [Column 3]: [What it measures]
- Color coding: Green=[definition], Yellow=[definition], Red=[definition]
Section 2: Detailed Analysis
For each [unit of analysis], create a "battlecard" containing:
- Quantitative Score (0-10): [What this measures]
- Strengths: [3-5 bullet points with specific focus]
- Challenges: [3-5 bullet points with specific focus]
- Strategic Summary: [100-150 words synthesizing the above]
- Actionable Recommendation: [One specific, implementable action]
Section 3: Comparative Intelligence
[Specific comparison framework, e.g., table, matrix, or ranked list]
Must include: [List specific elements]
Section 4: Implementation Roadmap
- Phase 1 (Months 1-X): [Specific milestones]
- Phase 2 (Months X-Y): [Specific milestones]
- Phase 3 (Months Y-Z): [Specific milestones]
- Key Risks: [Top 3-5 with mitigation strategies]
[VISUALIZATION REQUIREMENTS]
Include these specific visualizations:
1. [Type of chart]: Showing [what data]
2. [Type of chart]: Comparing [what data]
3. [Type of chart]: Mapping [what data]
Format: Use [ASCII/Markdown/specific notation] that can be easily reproduced
[MATHEMATICAL FRAMEWORK]
Calculate scores using this formula:
Overall Score = (Weight₁ × Factor₁) + (Weight₂ × Factor₂) + ... + (Weightₙ × Factorₙ)
Where:
- Factor₁ = [Specific calculation]
- Factor₂ = [Specific calculation]
- All weights must sum to 100%
[QUALITY CONTROLS]
Your output must:
- Not exceed [X] words total
- Include exactly [X] recommendations
- Feature actionable insights in every section title
- Provide rationale for every major claim
- Flag all assumptions with "≈" symbol
- Include confidence levels (High/Medium/Low) for projections
[CRITICAL SUCCESS FACTORS]
Before submitting, verify:
□ Every section includes actionable intelligence, not just data
□ Recommendations are specific and implementable
□ All scores/rankings are traceable to source data
□ Executive summary can stand alone for decision-making
□ Competitive dynamics are woven throughout, not siloed
□ Local context informs but doesn't overwhelm global perspective
□ All source material is fully verifyable and referenced.
[DELIVERABLE FORMAT]
Structure your response as a [specify format: report/dashboard/playbook] with:
- Clear hierarchical headings (##, ###)
- Tables in markdown format
- Bullet points for scannable insights
- **Bold** for key findings
- Executive-ready language (no jargon without explanation)
[END WITH]
Final Recommendation: [One paragraph that a CEO could read in an elevator]
Confidence Level: [High/Medium/Low with rationale]
Next Steps: [3 specific actions to take within 30 days]
To Note:
The more specific context you provide, the better the output
Reference existing operations to ground the analysis in reality
3-5 dimensions optimal (too many creates overload)
Each dimension should map to a decision criterion
Assign weights that reflect true business priorities
List exact metrics you need (not just "salary data" but "base + bonus + equity by level")
Build in fallback options for data gaps
Require source transparency for credibility
Set word/section limits to prevent sprawl
Include a checklist the AI must verify
Require confidence levels
So for example for this competition:
[ROLE & COGNITIVE PRIMING]
You are a Senior Partner at a tier-1 global strategy consulting firm, leading the Technology & Talent Intelligence practice. Your mission is to deliver a comprehensive location strategy analysis that will directly inform inDrive's decision on where to establish 2-3 major technology hubs globally. You must think and operate as a seasoned advisor who has guided Fortune 500 companies through similar expansions, balancing data-driven insights with practical implementation realities.
[STRATEGIC CONTEXT]
Client: inDrive - A global mobility and urban services platform operating in 50 countries with 200M+ downloads
Current State: 3,000 employees across 26 offices; major hubs in Limassol (650) and Almaty (700); growing presence in Brazil (500), Pakistan (415), Egypt (320), Mexico (310), Indonesia (250), and India (210)
Strategic Objective: Establish 2-3 cost-effective Global Capability Centers to scale technical teams by 500+ engineers within 18 months while optimizing costs by 40% vs Western Europe benchmarks
Decision Criteria: Talent density/quality, cost efficiency, operational viability, time zone alignment (GMT+2 ±3h), emerging market expertise
Constraints: Must leverage open-source data only; preference for markets with existing inDrive presence or similar economic dynamics
[ANALYTICAL ARCHITECTURE]
Your analysis must be structured across 4 key dimensions:
Dimension 1: Talent Ecosystem Intelligence (Weight: 40%)
- Component A: Target role density (Data Science, Product Management, Software Engineering)
- Component B: Talent velocity (YoY growth, university pipeline, competitor presence)
- Required Output: Quantified talent pools with quality indicators and competitive dynamics
Dimension 2: Economic Viability (Weight: 30%)
- Component A: Total compensation costs by role/level (base + bonus + equity)
- Component B: Operational costs (real estate, utilities, statutory costs)
- Required Output: Fully-loaded cost per employee with 3-year projections
Dimension 3: Regulatory & Business Environment (Weight: 20%)
- Component A: Ease of doing business (incorporation, employment law, IP protection)
- Component B: Risk factors (political stability, currency, corruption index)
- Required Output: Risk-adjusted operational readiness score
Dimension 4: Strategic Alignment (Weight: 10%)
- Component A: Cultural fit with inDrive's emerging market focus
- Component B: Scalability potential and infrastructure readiness
- Required Output: Future growth capacity assessment
[DATA SPECIFICATIONS]
For each analysis point, you must:
- Use only publicly available data from GitHub Innovation Graph, Stack Overflow Developer Survey, Glassdoor, Numbeo, World Bank, OECD, government sources
- When data is unavailable, provide ≈ estimates with clear rationale based on comparable markets
- Include data recency (preference for 2024-2025 data)
- Cite sources using this format: (Source: [type], 2025)
Priority data sources:
1. GitHub Innovation Graph for developer populations
2. Glassdoor/Levels.fyi for compensation benchmarking
3. World Bank Doing Business indicators
4. Numbeo Cost of Living Index
5. EF English Proficiency Index
[COMPETITIVE INTELLIGENCE REQUIREMENTS]
Analyze these specific competitors: Uber, Bolt, Grab, Ola, DiDi, Careem, Yassir
For each competitor, determine:
- Tech hub locations and approximate headcount
- Talent acquisition strategies in emerging markets
- Strategic implications for inDrive's expansion
[OUTPUT ARCHITECTURE]
Section 1: Executive Dashboard
- Lead with: Top 3 recommended cities globally with one-sentence rationale each
- Summary table with these exact columns:
* City, Country: Location name
* Expansion Score (0-100): Weighted composite score
* Talent Readiness: Abundant/Strong/Moderate/Limited
* Cost Index: 40-60% of Western Europe baseline
* 18-Month Hiring Feasibility: Realistic headcount achievable
- Color coding: Green=Optimal, Yellow=Viable, Red=Challenging
Section 2: Regional Deep-Dives
For each region (LATAM, APAC, Africa/Middle East), create location "battlecards" containing:
- Talent Ecosystem Score (0-10): Based on availability and quality
- Cost Advantage Score (0-10): Total savings vs baseline
- Operational Readiness Score (0-10): Infrastructure and business environment
- Strategic Fit Score (0-10): Alignment with inDrive's needs
- Recommended Talent Strategy: Specific approach for that market
- Key Risks: Top 3 with mitigation approaches
Section 3: Compensation Intelligence Matrix
Create a comprehensive table showing:
- Roles: Software Engineer, Product Manager, Data Scientist
- Levels: Junior (0-2y), Mid (3-5y), Senior (6-10y), Staff (10+y), Head
- Cities: Top 9 candidates (3 per region)
- Data: Base salary, total comp, employer costs
- Format: USD with % difference from Western Europe baseline
Section 4: Implementation Roadmap
- Phase 1 (Months 1-6): Location selection, entity setup, initial team
- Phase 2 (Months 7-12): Scale to 150-200 employees per hub
- Phase 3 (Months 13-18): Reach 250+ employees, establish leadership
- Critical Success Factors: Top 5 with specific KPIs
[VISUALIZATION REQUIREMENTS]
Include these specific visualizations:
1. Talent Density Heatmap: ASCII visualization showing developer populations
2. Cost-Talent Matrix: 2x2 matrix plotting cost efficiency vs talent availability
3. Risk Radar Chart: Multi-dimensional risk assessment per location
[MATHEMATICAL FRAMEWORK]
Calculate Expansion Score using:
Expansion Score = (0.4 × Talent Score) + (0.3 × Cost Score) + (0.2 × Environment Score) + (0.1 × Strategic Score)
Where each component score is normalized 0-100 based on:
- Talent Score = (0.6 × talent_density/max_density) + (0.4 × talent_growth/max_growth) × 100
- Cost Score = (1 - total_cost/western_europe_cost) × 100
- Environment Score = Average of normalized business ease, stability, infrastructure scores
- Strategic Score = Weighted assessment of market fit and growth potential
[QUALITY CONTROLS]
Your output must:
- Not exceed 3,000 words total
- Include exactly 3 global recommendations with 9 total cities analyzed
- Feature actionable insights in every section title
- Provide cost savings calculations for every recommendation
- Flag all assumptions with "≈" symbol
- Include confidence levels (High/Medium/Low) for 18-month projections
[CRITICAL SUCCESS FACTORS]
Before submitting, verify:
□ Every recommendation includes specific cost savings vs Western Europe
□ Talent availability is quantified for all target roles
□ Competitive dynamics are integrated throughout analysis
□ Implementation roadmap has concrete milestones
□ Risk mitigation strategies are practical and specific
□ Local insights enhance but don't overwhelm global perspective
[DELIVERABLE FORMAT]
Structure your response as an executive-ready strategy report with:
- Clear hierarchical headings (##, ###)
- Tables in markdown format for easy copying
- Bullet points for scannable insights
- **Bold** for key findings and recommendations
- Executive-ready language with acronyms explained on first use
[END WITH]
Final Recommendation: One paragraph that inDrive's CEO could present to the board
Confidence Level: High/Medium/Low with supporting rationale
Next Steps: 3 specific actions to initiate within 30 days
Check out the output of this prompt on these platforms (including my typos):
POWER TIPS FROM THE CHAMPIONS APPROACHES
Patricia's Dashboard Approach: Always require visual organization (colors, scores, rankings) to make insights immediately apparent
Barry's Multi-Step Process: For complex analyses, specify a research sequence rather than just outcome requirements
Daniel's Table Pre-Formatting: When you need specific data, provide the exact structure to fill
Balaji's Hierarchical Decomposition: Break complex requests into nested categories for clarity
Remy's Modular Architecture: For very complex requests, consider splitting into data gathering and presentation phases
The Future of Talent Intelligence
The One and Done Challenge demonstrated that we're entering a new era of business intelligence, where the ability to architect sophisticated prompts is becoming as valuable as traditional analytical skills. The winners didn't just use AI—they conducted it like master orchestrators, each with their own style but all achieving symphonic results.
As Yuri Misnik observed, what made these submissions truly worthy was their ability to include "commercial, regulatory and competitor insights"—the full spectrum of factors that make location decisions complex and consequential. The challenge proved that with the right prompt engineering, AI can move beyond simple question-answering to become a true strategic partner.
The variation in approaches—from Barry's consulting framework to Remy's software architecture paradigm, from Patricia's dashboard visualization to Daniel's tabular precision—suggests that prompt engineering is not converging on a single best practice but rather flowering into multiple schools of thought, each suited to different challenges and contexts.
Perhaps most importantly, the One and Done Challenge showed that the future of AI in business isn't about replacing human intelligence but about amplifying it. Each winning prompt was a crystallization of human expertise, judgment, and creativity. The AI systems were powerful, but they were only as insightful as the prompts that guided them.
As organizations like inDrive expand globally, the ability to rapidly synthesize complex, multi-dimensional intelligence about new markets will become increasingly critical. The One and Done Challenge didn't just identify optimal locations for tech hubs—it revealed the emergence of a new discipline that will shape how businesses make strategic decisions in an AI-augmented world.
The winners of this challenge weren't just good at talking to AI. They were translators between human strategic needs and machine analytical capabilities, architects of intelligent systems, and pioneers of a new form of business communication. Their prompts weren't just instructions—they were blueprints for intelligence itself.
Beyond the Prompt: Human Judgment and the Boundaries of Generative AI
While the One and Done Challenge revealed the remarkable breadth of intelligence that can be aggregated and synthesized with a single, well-constructed prompt, it also surfaced a critical reality: the data—and the AI—have limits.
One recurring observation across multiple submissions was a noticeable over-indexing on technical roles—particularly software engineering and data science—even when broader talent categories were requested. This likely reflects a bias in the underlying corpus: the digital universe is simply more saturated with documentation, blogs, repositories, and compensation data about engineering talent than, say, supply chain specialists, hardware designers, or UX researchers. Without explicit instruction, generative AI systems tend to amplify what's most statistically represented—not what's most strategically relevant.
This underscores a fundamental truth: AI reflects the data it's trained on, not the world as it is, and certainly not the world as it ought to be seen for a strategic decision. Unless carefully prompted, the outputs can be impressively articulate but subtly skewed—like a map that’s colorful and detailed but missing key roads.
Moreover, even the most elegant prompts could only go so far in producing deep critical analysis or executive judgment. Aggregation was breathtaking; interpretation was often surface-level. Few outputs could fully replicate the nuanced thinking required to reconcile data conflicts, interrogate assumptions, or challenge strategic framing. These are still squarely in the domain of human expertise, intuition, and accountability.
The promise of Talent Intelligence in an AI-powered future is immense—but it will only be fully realized when paired with human discernment. AI can now draft the intelligence brief, but humans still write the business case. The best prompt engineers are not just wordsmiths; they are sense-makers, strategists, and editors-in-chief of machine-generated thinking.
As we move forward, the frontier of Talent Intelligence will depend not just on asking AI for more—but on asking it better. And just as importantly, on knowing what not to outsource to the machine.